The General Video Game Agent ‘‘MaastCTS2’’
Introduction
This post provides an informal description of my MaastCTS2 agent for General Video Game Playing. It participated in the Single-Player and Two-Player tracks of the GVG-AI Competition in 2016. The results can be found here. MaastCTS2 ended up winning the Single-Player track, and was the runner-up in the Two-Player track. The source code of the agent can be found on github. This post is intended to shortly describe the main techniques used by the agent in an informal manner. More detailed and formal descriptions of some of the techniques used can be found in a CIG paper1 and my Master Thesis2 (for which I will edit in links when they become available at a later time). It should be noted that there was still time left until the submission deadlines for the competitions after writing these documents, which means that development continued and some features have been added after writing them. I will write an update with new references if more of those details end up being published.
Because I don’t want this post to become too long and detailed, I will assume the reader to have a decent amount of prior knowledge on Artificial Intelligence (AI) in games, and, in particular, Monte-Carlo Tree Search (MCTS). MCTS is the core algorithm used by MaastCTS2, but it is heavily modified with a large number of enhancements. I will describe some of the most interesting/important enhancements after a quick discussion of the GVG-AI competition and framework. The focus will be on the Single-Player variant of the agent. This is the track that I spent most time on.
GVG-AI Competition and Framework
The GVG-AI Competition is organised to compare approaches for General Video Game Playing (GVGP). The basic idea of GVGP is to develop agents that should be able to play many different kinds of (2-dimensional) video games, without knowing ahead of time which games are going to be played. This is done using the GVG-AI framework, which specifies a certain file format in which many kinds of video games and levels can be defined. Examples of well-known games that can be played through the framework are PacMan and Space Invaders (named Aliens in the framework), but there are many more.
In the competition, an agent is allowed to select an action to play once every 40 milliseconds (these points in time are referred to as frames or ticks).
Typically there are 3-5 actions to choose from. Every frame, the agent has access to the current game state. Search algorithms, such as MCTS, can be implemented using
advance(action) and copy() functions. There is no undo() operation to revert to a previous game state, so if you want to generate multiple successors of a single
state you need to copy it a few times first.
It is important to note that the advance and copy operations are rather slow (especially in comparison to equivalent operations in board games). In a typical board
game, an advance operation would consist of modifying a few entries in an array, or flipping a few bits in some bitboards, and possibly incremental updates of variables
required for optimized implementations of other functions (for example, updating the Zobrist hash value used for transposition tables). In GVG-AI, the advance operation
does much more work, including the following two points which are particularly expensive:
- Looping through all objects (“sprites”) to update their locations (possibly involving some simple physics, such as gravity, or simple behaviors for chasing/fleeing).
- Event handling (this includes collision detection, which again involves looping through objects).
It is easy to see why the advance function in GVG-AI is expensive in comparison to typical board games. This has two important consequences for MCTS:
- We will often have to decide which action to play based on a low number of simulations (which are also all cut off at a relatively low depth).
- In comparison to domains with cheaper
advanceandcopyfunctions, we can afford to include many other (computationally expensive) bells and whistles, as long as they don’t rely onadvanceorcopythemselves. We’re doomed to have a low simulation count anyway, so we should try to make every individual simulation as informative as possible!
With this in mind, I am going to discuss three points that are, in my opinion, important insights for making MCTS work well in GVG-AI. Some of the most interesting enhancements implemented in MaastCTS2 are also discussed, but not all of them. More details on those can be found in the references.
Making MCTS Optimistic (or Less Pessimistic)
MCTS is often described as a Best-First Search algorithm, meaning that it spends the most time exploring parts of the search tree that appear to be promising so far (based on previous simulations), a bit less time on parts of the search tree that appear to be “neutral”, and the lowest amount of time on parts of the search tree that appear to be bad so far. This is fine when you have a decent number of simulations, because you will still use at least some of them to explore parts that appeared to be bad according to the first few simulations. If the first couple of simulations in those parts of the tree were simply bad luck, MCTS will then adjust the initial “bad” estimates in a more neutral direction, and continue spending a bit more time there. In the case of GVG-AI, with a low number of simulations, it is likely that a single simulation that happened to end in a loss through (semi-)random play makes MCTS immediately disregard an entire part of the tree and never visit it again, simply because it doesn’t have the time.
This can be addressed by significantly increasing the value of the \(C\) parameter of the well-known UCB1 formula (the exploration parameter). The problem with this is that it basically turns MCTS from a Best-First Search algorithm into an algorithm that randomly explores the entire search space. I’m going to argue that what we actually want, is that it still prioritizes parts of the tree that are estimated to be good so far (parts where simulations ended in wins or score gains), but we want to have a similar priority level for parts with “neutral” and parts with “bad” evaluations. This is because there is no opposing player that can play towards states that are bad for us (note that I’m focusing on the Single-Player track), and in many games in the framework the agent is capable of avoiding danger reactively. With “reactively”, I mean that it can afford to get very close to dangerous situations, and then still avoid it. The main reason for this is that, in the majority of the games currently in the framework, objects that can kill the agent upon collision are:
- Stationary, meaning that it’s perfectly fine for the agent to walk up very close, or
- Only moving in a straight line (for instance, bullets), meaning that the agent only needs to make sure there is an empty cell nearby that it can dodge into at the very last moment, or
- At most as fast as the agent, and sometimes slower. This means that, as long as the agent doesn’t get trapped in some corner, it can keep running away from enemies.
There are probably some games where this is not the case, and the agent should take losses observed deeper down in the search tree seriously, but those are exceptions. What this means is that I only want to start taking losses observed at the end of MCTS simulations seriously when we’re rather sure that there are no options available to reactively avoid a loss. This idea was initially implemented as Loss Avoidance.1,2 The basic idea of Loss Avoidance is to only backpropagate a loss if it is already observed in the selection step of MCTS, and do a quick Breadth-First Search among the siblings of a losing node to find a better alternative if it is observed in the play-out step of MCTS. For the CIG version of the agent, I extended the idea even further by changing the evaluation of a simulation ending in a loss even during the backpropagation step. This was done in such a way that the large negative value associated with a loss (\(-10^{7}\)) is only backpropagated into nodes that cannot possibly have any successors with a \(0\%\) chance of losing. This idea is even closer to the idea of using Minimax in MCTS than Loss Avoidance already was. The main differences are that it only cares about “proving” losses (we don’t care too much about proving wins), and it is adjusted to deal with nondeterministic games (which is why I put “proving” in quotation marks).
Note that we only care about treating losses in a special way, because we want to avoid disregarding parts of the search tree where losses were observed too quickly. When (semi-)random simulations end in wins, we’re perfectly happy and don’t need to treat those in any special way. It is very likely that we will be able to reach such a win once we’ve found it due to the absence of an opposing player (though not certain, due to nondeterminism in games), and the standard implementation of MCTS will already start dedicating even more time in such a part of the search tree.
Pruning Redundant Paths Using Novelty Tests
Novelty tests were originally introduced in the Iterated Width (IW)3 planning algorithm. This algorithm was later shown4 to outperform a vanilla MCTS implementation in GVG-AI. It was also used by some agents that performed well in the competition, such as the YBCriber agent, which won the leg of the GVG-AI competition in 2015 at the CEEC 2015 conference, and the NovelTS agent, which ranked seventh at CIG 2016.
The basic idea of novelty tests in IW is to prunes states that are generated in a Breadth-First Search process if they are “too similar” to states generated previously
in the same search process. I refer to the original publications for the more formal explanations. To get a better idea of what kinds of states can be pruned by
novelty tests, see the following figure of the game Labyrinth:
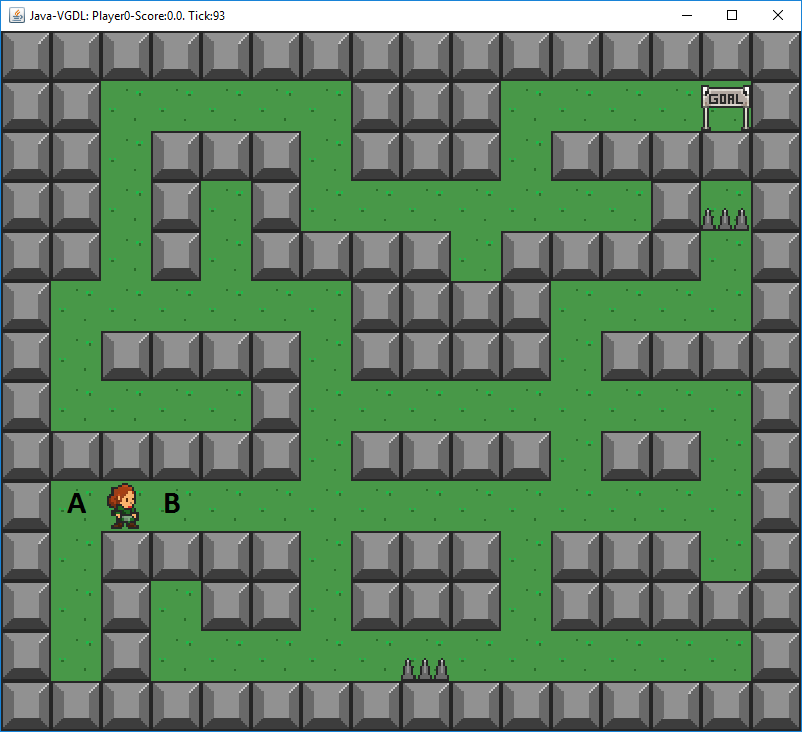 Suppose that the agent previously moved from A to its current location. The states obtained by moving up or down can get pruned in this situation, because such
actions do not actually change the game state at all; the agent attempts to move, but is blocked by a wall and stays in the same position. The state generated by moving
to the left can also be pruned if the agent was located in A in the previous game state, because moving to the left generates a new state that is equivalent to one
that we have seen before. In this specific case, pruning based on novelty tests is clearly very powerful, because it actually leaves only one action. In most cases the
effect will not be this extreme, but it can still be very powerful. Even if only one out of four movement actions are pruned due to being blocked by an obstacle, that
is already a reduction of \(25\%\) of the successors of such a state!
Suppose that the agent previously moved from A to its current location. The states obtained by moving up or down can get pruned in this situation, because such
actions do not actually change the game state at all; the agent attempts to move, but is blocked by a wall and stays in the same position. The state generated by moving
to the left can also be pruned if the agent was located in A in the previous game state, because moving to the left generates a new state that is equivalent to one
that we have seen before. In this specific case, pruning based on novelty tests is clearly very powerful, because it actually leaves only one action. In most cases the
effect will not be this extreme, but it can still be very powerful. Even if only one out of four movement actions are pruned due to being blocked by an obstacle, that
is already a reduction of \(25\%\) of the successors of such a state!
In MaastCTS2, I have modified the novelty tests to be applicable in a Best-First Search such as MCTS, instead of a Breadth-First Search (as is the case in IW). The required modifications for this slightly reduce the pruning power, meaning that there are some states that would get pruned in IW, but are not pruned in MCTS, but it is still effective. The details on this are outside the scope of this post, and are described in more detail elsewhere.1,2 It should be noted that these novelty tests are not cheap computationally. In GVG-AI, this does not have a large impact on the number of simulations due to the relatively high cost of individual simulations. I suspect this may be more problematic in domains with faster simulations, such as typical board games, but I have not tested this (and I do believe it would be interesting to try still).
Heuristic Evaluation Function
A standard implementation of MCTS in GVG-AI (such as the implementation of the sample MCTS controllers included in the framework) uses an evaluation function based on the win status (win, loss, or game not over) and the observed game score to evaluate simulations (many simulations need to be cut off before reaching a terminal state). In many games, there are no (or very few) score gains, and terminal states can also be far away from the initial state. In such games, many MCTS simulations end in an evaluation of \(0\). When that happens, MCTS actually behaves more like a random search than a Best-First Search. The solution for this is to incorporate more domain knowledge in a heuristic evaluation function. This is difficult in GVG-AI, because we don’t know which games we’re playing, and maybe also a bit against the spirit of the competition (which is intended to motivate the use of generally applicable techniques). However, it is still possible to some extent, and also turns out to be very useful.
This approach is not new to MaastCTS2, and has been extensively investigated by many others before. Some examples of publications discussing this can be found in the references5,6,7 below. I suspect that the majority of the participants in the competitions in 2015 and 2016 (and maybe even 2014 already) used heuristic evaluation functions in some way. Therefore, I will not make this post any longer than it needs to be by discussing this in much detail. I still feel like it should be mentioned, because my experiments indicated that the inclusion of a heuristic evaluation function had a very significant impact on the average win percentage.
Final Notes
The three points discussed above do not include all of the enhancements that have been implemented in MaastCTS2. I suppose the post is already fairly long as it is, so I decided to stick to only those enhancements that I personally think are the most interesting ones (mostly because they are new), and the most impactful ones. Much more detailed and formal descriptions of most of the features of MaastCTS2 can be found in the references below, but not everything. Hopefully details on the most recent changes, implemented after submission of the publications listed below, will still be described somewhere in the future.
Please let me know if you liked this post, if you think something is unclear or missing, if you have any questions, or if the page is horribly broken (which may be the case since this is my first post here)!
References
[1]: Soemers, D.J.N.J., Sironi, C.F., Schuster, T., and Winands, M.H.M. (2016). Enhancements for Real-Time Monte-Carlo Tree Search in General Video Game Playing. In 2016 IEEE Conference on Computational Intelligence and Games (CIG 2016).
[2]: Soemers, D.J.N.J. (2016). Enhancements for Real-Time Monte-Carlo Tree Search in General Video Game Playing. M.Sc. thesis, Maastricht University, Maastricht, the Netherlands.
[3]: Lipovetzky, N. and Geffner, H. (2012). Width and Serialization of Classical Planning Problems. In Proceedings of the Twentieth European Conference on Artificial Intelligence (ECAI 2012) (eds. L. De Raedt, C. Bessiere, D. Dubois, P. Doherty, P. Frasconi, F. Heintz, and P. Lucas), pp. 540-545, IOS Press.
[4]: Geffner, T. and Geffner, H. (2015). Width-Based Planning for General Video-Game Playing. In Proceedings of the Eleventh Artificial Intelligence and Interactive Digital Entertainment International Conference (eds. A. Jhala and N. Sturtevant), pp. 23-29, AAAI Press.
[5]: Chu, C. Y., Hashizume, H., Guo, Z., Harada, T., and Thawonmas, R. (2015). Combining Pathfinding Algorithm with Knowledge-based Monte-Carlo Tree Search in General Video Game Playing. In Proceedings of the IEEE Conference on Computational Intelligence and Games, pp. 523-529, IEEE.
[6]: Eeden, J. van (2015). Analysing And Improving The Knowledge-based Fast Evolutionary MCTS Algorithm. M.Sc. thesis, Utrecht University, Utrecht, the Netherlands.
[7]: Perez, D., Samothrakis, S., and Lucas, S. (2014). Knowledge-based Fast Evolutionary MCTS for General Video Game Playing. In Proceedings of the IEEE Conference on Computational Intelligence and Games, pp. 68-75, IEEE.
Leave a comment